Искусственный интеллект прочно укоренился в различных сферах деятельности, и наука не является исключением. Многие ученые активно используют его в процессе написания научных работ. Именно поэтому перед публикацией научные журналы тщательно проверяют статьи на наличие следов ИИ. Впрочем, действительно ли такие детекторы эффективны? Дают ли они стопроцентную гарантию достоверности результатов? Сегодня поговорим об этом подробнее.

ИИ-детекторы: Эффективно ли они работают?
Соблюдение принципов академической добропорядочности — это основа научной деятельности. Поэтому перед тем, как отправить статью на рецензирование, научные журналы проверяют ее на возможные признаки использования искусственного интеллекта. Для этого существуют специальные инструменты, которые анализируют текст и предоставляют отчет об уникальности. Однако на практике такие ИИ-детекторы работают далеко не безупречно. Наоборот, они имеют немало недостатков, которые могут существенно повлиять на объективность результатов. Как именно они проявляются?
Недостаток 1: ложноположительные результаты из-за академического стиля
Научные тексты по своей природе имеют схожий стиль написания, поскольку в них используются устоявшиеся термины, типичные конструкции предложений и нейтральный тон. В процессе анализа детекторы ищут именно эти признаки, в частности повторяющиеся языковые шаблоны, формальное изложение и четкую структуру. Они являются так называемыми «маркерами», которые должны свидетельствовать о том, что автором текста является не человек, а инструмент на основе искусственного интеллекта.
В результате возникает парадокс: автор, который хорошо владеет научным стилем, использует правильную терминологию и соблюдает стандарты, автоматически попадает под подозрение. Чем лучше написана статья, тем выше вероятность, что детектор ошибочно определит ее как текст, созданный искусственным интеллектом. Как следствие, он выдает ложноположительные результаты и высокий процент использования ИИ.
Недостаток 2: непонимание того, как на самом деле авторы используют технологии ИИ
В научном сообществе существует мнение, что исследователи используют технологии искусственного интеллекта исключительно для генерации полного текста статьи. Однако на самом деле это — предубеждение, ведь современные ученые применяют ИИ как помощника на разных этапах работы, например, для генерации идей во время мозгового штурма, для структурирования большого количества данных, для перефразирования сложных формулировок, для исправления грамматики в текстах на иностранном языке или для улучшения читабельности отдельных абзацев. Это точечное, осознанное использование инструмента, где основные идеи, методология и выводы остаются авторскими.
Но детекторы не видят этой разницы. Для алгоритма не имеет значения, сгенерировали ли вы всю статью одним запросом или использовали языковую модель только для улучшения двух предложений. Любое использование вспомогательных технологий автоматически маркирует статью как «написанную искусственным интеллектом», что не соответствует действительности.
Недостаток 3: невозможность оценить реальный вклад автора
Как мы отметили выше, ИИ все чаще выступает в качестве технического помощника, который помогает ученому лучше выразить свои мысли, а не в качестве заменителя человеческого мышления. Например, когда математик использует калькулятор для вычислений, это не означает, что он не является автором исследования.
Точно так же использование языковых моделей для редактирования или форматирования текста не отменяет того, что автор вложил в работу. Но детекторы не умеют это оценивать. Они не различают, разработал ли автор сам методологию, провел эксперимент, проанализировал данные и сделал выводы (использовав ИИ только для технического улучшения текста), или просто сгенерировал всю статью автоматически. Такая ограниченность приводит к неправильным выводам о качестве и оригинальности научной работы.
Недостаток 4: создание серьезных этических проблем в академической среде
Когда детекторы ошибочно определяют научные работы как созданные искусственным интеллектом, это порождает цепь этических конфликтов. Авторы могут получить несправедливые обвинения в нарушении академической добропорядочности, хотя на самом деле они честно работали над своим исследованием. Это подрывает доверие между учеными и редакциями журналов, а также может нанести ущерб научной репутации исследователей.
Особенно уязвимыми становятся молодые ученые или те, кто публикуется на иностранном языке, поскольку их тексты чаще попадают под подозрение из-за менее естественного языка или попыток отшлифовать стиль с помощью технологий. Кроме того, ложные обвинения могут привести к отклонению качественных исследований, задержке публикаций и потере возможностей для карьерного роста. Определение подлинного авторства требует гораздо более глубокого анализа, чем автоматическая проверка программой.
Примеры ошибок в работе ИИ-детекторов
Для того чтобы понять, как проявляется нестабильность ИИ-детекторов на практике, рассмотрим три реальных кейса.
Практический кейс 1: ухудшение результатов после правок
В этом случае авторы научной статьи столкнулись с ситуацией, которая наглядно демонстрирует ненадежность ИИ-детекторов. Первичная проверка статьи журналом показала результат 28% вероятного использования искусственного интеллекта. Редакция попросила снизить этот показатель до 20% и предоставила подробный отчет, в котором конкретные фрагменты текста были помечены как «AI-like».

Авторы переписали исключительно те фрагменты, которые детектор определил как проблемные, не затрагивая остальной текст. Однако после повторной проверки тот же журнал предоставил отчет с результатом 89%. Фактически показатель вырос более чем в три раза вместо ожидаемого снижения.

Эта ситуация раскрывает одну из ключевых проблем ИИ-детекторов: они не имеют стабильных критериев оценки и дают непредсказуемые результаты даже после исправлений.
Практический кейс 2: разные результаты для одного текста
Еще более показательным является случай, когда одна и та же версия статьи, проверенная одной и той же системой, но в разных журналах, получила существенно разные результаты. В первом научном издании система показала 49% использования искусственного интеллекта.
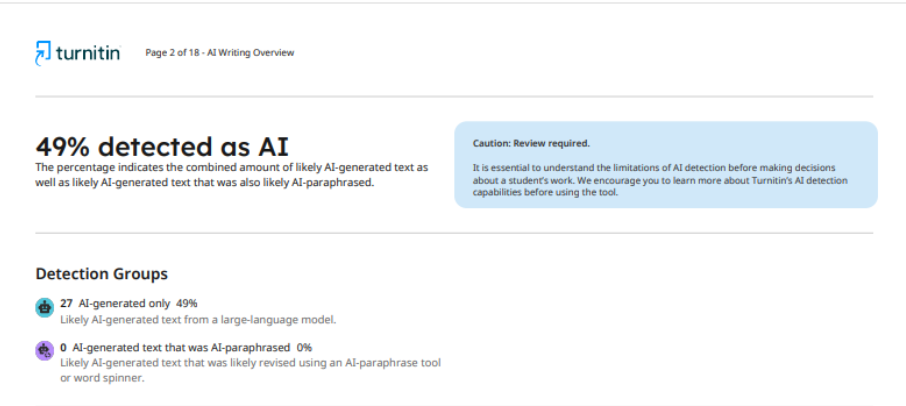
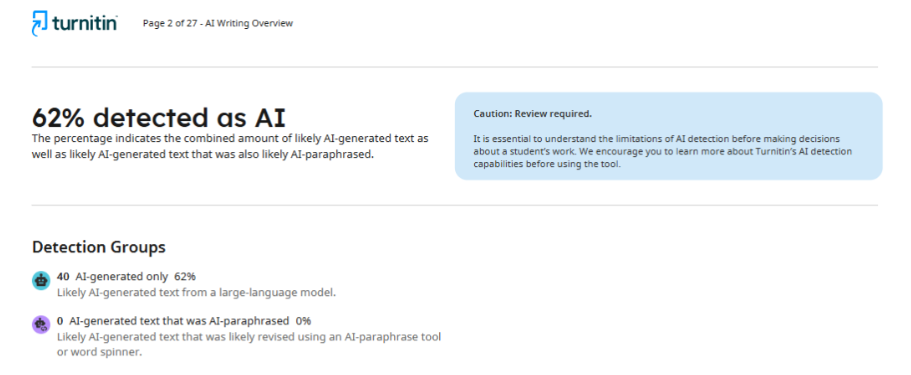
Что касается второго журнала, то после проверки статьи он предоставил автору отчет, в котором было указано 62% использования ИИ. Такая непоследовательность в результатах указывает на то, что детекторы не могут обеспечить стабильную и точную оценку, а их способность определять, использовались ли технологии искусственного интеллекта в процессе написания, остается под вопросом.
Практический кейс 3: разница в результатах разных программ
Стоит отметить, что не существует универсальной программы, которую будут использовать все научные журналы. Каждое научное издание самостоятельно выбирает инструменты для проверки статей на наличие следов искусственного интеллекта. Именно этот аспект существенно влияет на объективность результатов.
Например, в этом случае для анализа одной статьи было использовано два разных детектора: Turnitin и Pangram. В отчете, предоставленном первой платформой, указано, что текст на 45% сгенерирован искусственным интеллектом.
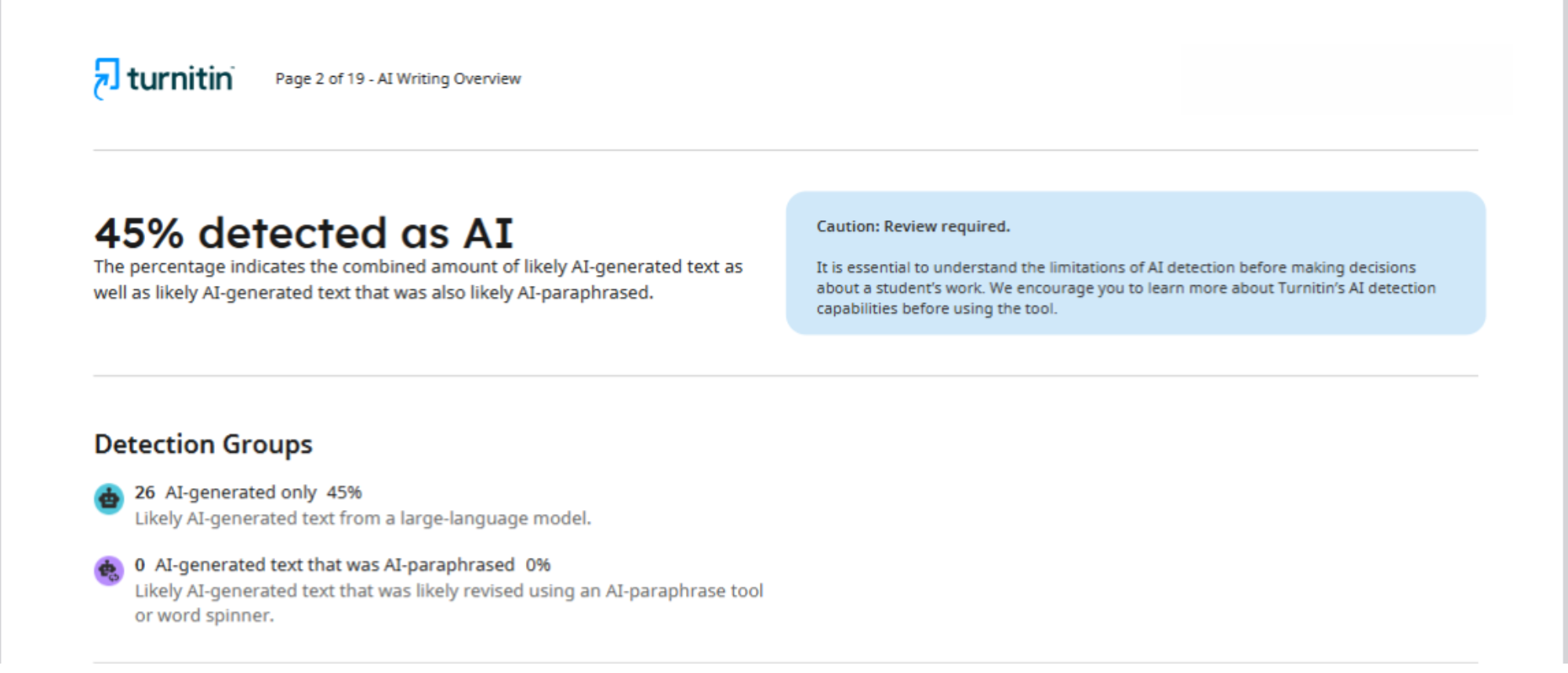
Что касается Pangram, то он определил, что статья является результатом работы ИИ на 75%. Как видим, разница между полученными результатами – колоссальная.

Эта ситуация наглядно демонстрирует, что каждый инструмент для проверки текстов имеет свои собственные алгоритмы, критерии и подходы к распознаванию сгенерированного контента. Отсутствие единых стандартов детекции означает, что судьба научной статьи может зависеть не от ее реального качества и оригинальности, а от того, какую именно программу выбрал конкретный журнал.
Стоит ли доверять инструментам проверки наличия ИИ?
Приведенные примеры и вышеупомянутые недостатки свидетельствуют о том, что современные детекторы искусственного интеллекта имеют существенные ограничения и неточности, которые ставят под сомнение их надежность как единственного критерия оценки. Они могут давать непредсказуемые результаты, не всегда учитывают контекст использования технологий и иногда ошибочно идентифицируют качественно написанные академические тексты как созданные ИИ. Когда один и тот же текст получает разные оценки в разных проверках, а попытки исправить отмеченные фрагменты приводят к неожиданным результатам, становится очевидным, что эти инструменты еще не достигли необходимого уровня точности.
Поэтому использовать их в качестве основного или единственного критерия при принятии решений о публикации рискованно. Даже сами разработчики этих систем отмечают, что их программы не являются совершенными и могут ошибаться, а результат проверки является лишь вероятностным предположением о происхождении текста, а не окончательным доказательством.
Прежде всего, академическое сообщество должно развивать прозрачную политику в отношении этического использования ИИ, акцентировать внимание на оценке содержательной оригинальности, методологии и научного вклада автора. Только такой подход позволит сохранить академическую добропорядочность, одновременно адаптируясь к стремительному развитию современных технологий.


