Artificial intelligence has become firmly established in various fields of activity, and science is no exception. Many scientists actively use it in the process of writing scientific papers. That is why scientific journals carefully check articles for traces of AI before publication. However, are such detectors really effective? Do they provide a 100% guarantee of the reliability of the results? Today we will talk about this in more detail.

AI detectors: How effective are they?
Adherence to the principles of academic integrity is the foundation of scientific activity. Therefore, before sending an article for review, scientific journals check it for possible signs of artificial intelligence use. For this purpose, there are special tools that analyse the text and provide a report on its uniqueness. However, in practice, such AI detectors are far from flawless. On the contrary, they have many shortcomings that can significantly affect the objectivity of the results. How exactly do they manifest themselves?
Disadvantage 1: false positive results due to academic style
Scientific texts are similar in style by their very nature, as they use established terms, typical sentence structures and a neutral tone. During the analysis, detectors look for these very characteristics, in particular repetitive language patterns, formal presentation, and clear structure. These are so-called ‘markers’ that are supposed to indicate that the author of the text is not a human being, but an artificial intelligence-based tool.
This results in a paradox: an author who is proficient in scientific style, uses correct terminology, and adheres to standards automatically comes under suspicion. The better an article is written, the higher the probability that the detector will mistakenly identify it as text created by artificial intelligence. As a result, it produces false positives and a high percentage of AI usage.
Disadvantage 2: misunderstanding of how authors actually use AI technology
There is a perception in the scientific community that researchers use artificial intelligence technology exclusively to generate the full text of an article. However, this is actually a bias, as modern scientists use AI as an assistant at various stages of their work, for example, to generate ideas during brainstorming, to structure large amounts of data, to rephrase complex formulations, to correct grammar in foreign language texts, or to improve the readability of individual paragraphs. This is a targeted, conscious use of the tool, where the main ideas, methodology, and conclusions remain the author's.
But detectors do not see this difference. It does not matter to the algorithm whether you generated the entire article with a single query or used the language model only to improve two sentences. Any use of assistive technologies automatically marks the article as ‘written by artificial intelligence,’ which is not true.
Disadvantage 3: inability to assess the author's actual contribution
As we noted above, AI is increasingly acting as a technical assistant that helps scientists better express their thoughts, rather than as a substitute for human thinking. For example, when a mathematician uses a calculator for calculations, this does not mean that he is not the author of the research.
Similarly, the use of language models for editing or formatting text does not negate the author's contribution to the work. But detectors are unable to evaluate this. They do not distinguish whether the author developed the methodology themselves, conducted the experiment, analysed the data and drew conclusions (using AI only for technical improvement of the text), or simply generated the entire article automatically. This limitation leads to incorrect conclusions about the quality and originality of scientific work.
Disadvantage 4: Creation of serious ethical problems in the academic environment
When detectors mistakenly identify scientific works as created by artificial intelligence, it creates a chain of ethical conflicts. Authors may be unfairly accused of violating academic integrity, even though they have worked honestly on their research. This undermines trust between scientists and journal editors and can damage the scientific reputation of researchers.
Young researchers or those who publish in a foreign language are particularly vulnerable, as their texts are more likely to come under suspicion due to less natural language or attempts to polish their style using technology. In addition, false accusations can lead to the rejection of high-quality research, delays in publication, and lost career opportunities. Determining true authorship requires much deeper analysis than an automatic program check.
Examples of errors in the work of AI detectors
To understand how the instability of AI detectors manifests itself in practice, let's look at three real-life cases.
Practical case 1: deterioration of results after edits
In this case, the authors of a scientific article encountered a situation that clearly demonstrates the unreliability of AI detectors. The journal's initial review of the article showed a 28% probability of artificial intelligence use. The editors asked to reduce this figure to 20% and provided a detailed report in which specific text fragments were marked as ‘AI-like’.

The authors rewrote only those fragments that the detector identified as problematic, leaving the rest of the text untouched. However, after rechecking, the same journal provided a report with a result of 89%. In fact, the indicator increased more than threefold instead of the expected decrease.

This situation reveals one of the key problems with AI detectors: they do not have stable evaluation criteria and give unpredictable results even after corrections.
Practical case 2: different results for the same text
Even more telling is the case where the same version of an article, checked by the same system but in different journals, received significantly different results. In the first scientific publication, the system showed 49% use of artificial intelligence.
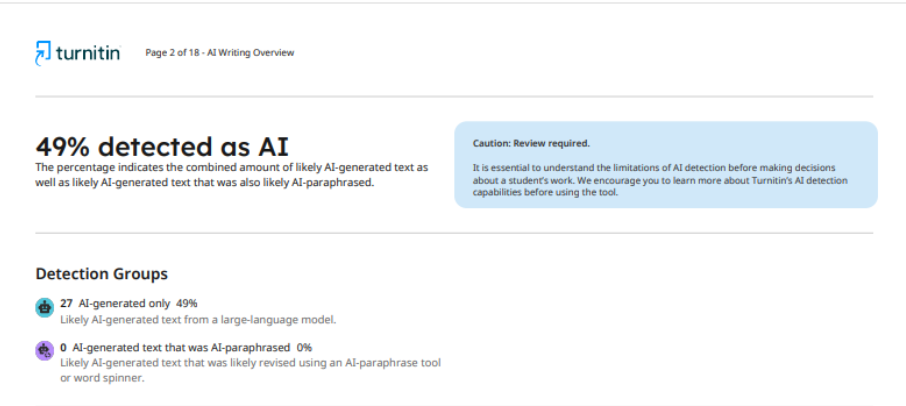
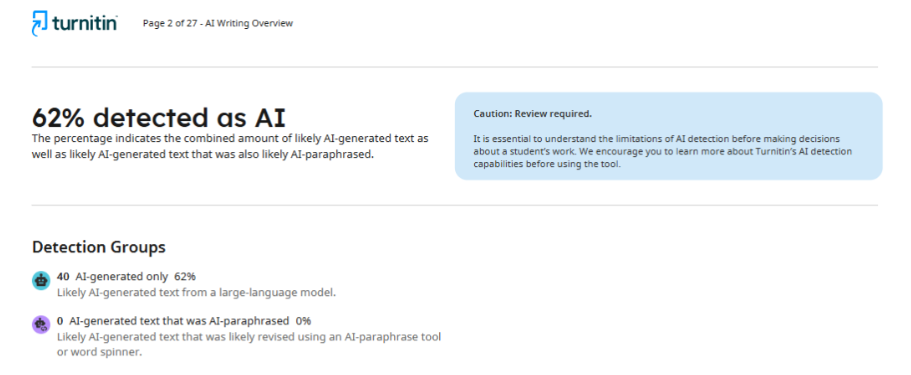
As for the second journal, after checking the article, it provided the author with a report indicating 62% AI usage. Such inconsistency in results indicates that detectors cannot provide a stable and accurate assessment, and their ability to determine whether artificial intelligence technologies were used in the writing process remains questionable.
Practical case 3: differences in the results of different programmes
It is worth noting that there is no universal programme that all scientific journals use. Each scientific publication independently selects tools to check articles for traces of artificial intelligence. It is this aspect that significantly affects the objectivity of the results.
For example, in this case, two different detectors were used to analyse one article: Turnitin and Pangram. The report provided by the first platform states that 45% of the text was generated by artificial intelligence.
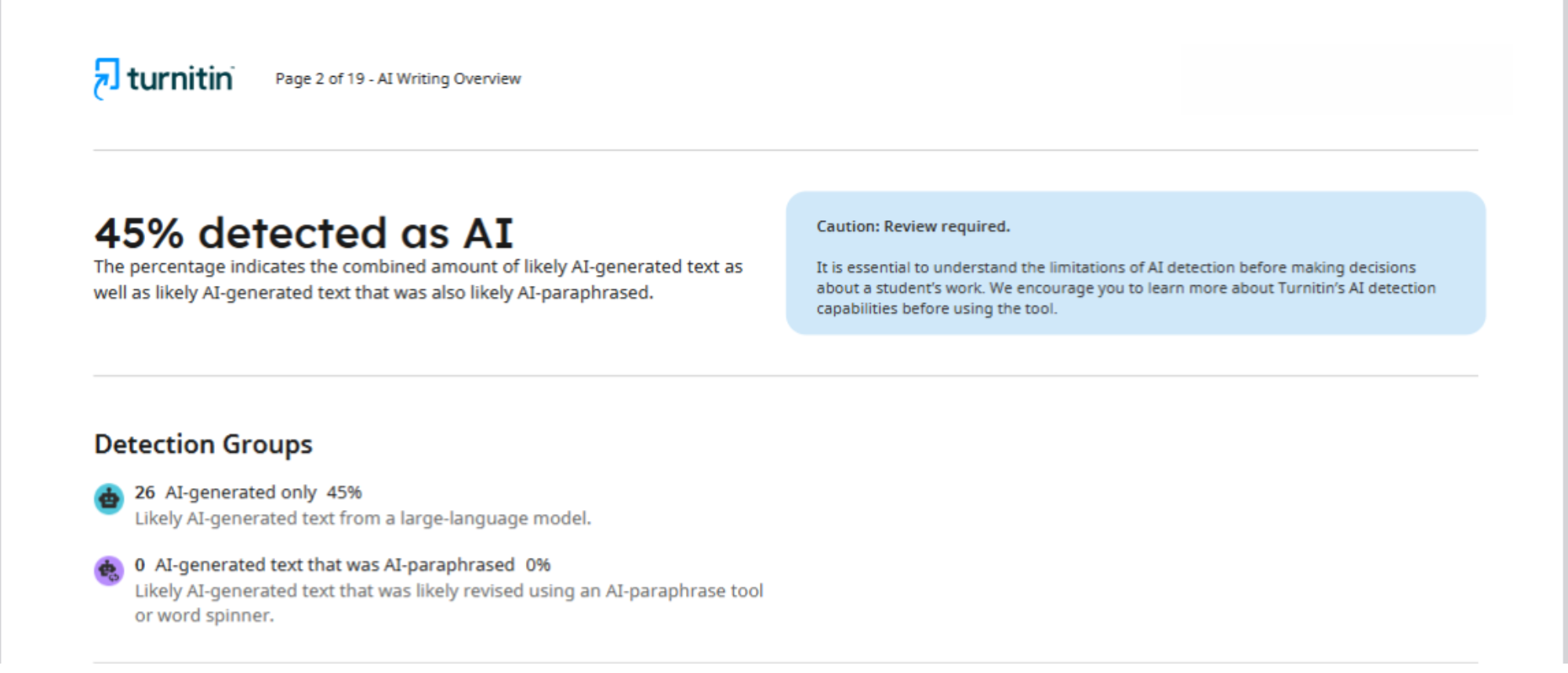
As for Pangram, it determined that the article was 75% the result of AI. As we can see, the difference between the results obtained is enormous.

This situation clearly demonstrates that each text verification tool has its own algorithms, criteria, and approaches to recognising generated content. The lack of uniform detection standards means that the fate of a scientific article may depend not on its actual quality and originality, but on which programme a particular journal has chosen.
Should AI detection tools be trusted?
The examples given and the shortcomings mentioned above show that modern artificial intelligence detectors have significant limitations and inaccuracies that call into question their reliability as the sole criterion for evaluation. They can produce unpredictable results, do not always take into account the context of technology use, and sometimes mistakenly identify well-written academic texts as AI-generated. When the same text receives different ratings in different checks, and attempts to correct the marked fragments lead to unexpected results, it becomes clear that these tools have not yet reached the required level of accuracy.
Therefore, using them as the main or sole criterion when making decisions about publication is risky. Even the developers of these systems themselves note that their programmes are not perfect and can make mistakes, and that the result of the check is only a probabilistic assumption about the origin of the text, not definitive proof.
First and foremost, the academic community must develop transparent policies on the ethical use of AI, focusing on the assessment of the author's originality, methodology and scientific contribution. Only such an approach will preserve academic integrity while adapting to the rapid development of modern technologies.


